

Inside Our Quality Backlog Reduction Playbook
The methodology we use when backlogs become a crisis. Here's how to dig out and stay out.


At some point, almost every Quality team will stare down a backlog that’s gotten out of control. Maybe it’s deviations growing at 20 a day. Maybe it’s complaints that have missed their closeout deadlines. Maybe it’s CAPAs that have been sitting open for years, preventing you from addressing the underlying problems that keep generating repeat deviations.
We’ve been called on to embed contracted professionals to attack these backlogs within Quality departments many times. What follows is the methodology we've developed from that work — the approach we use when a backlog has become a genuine crisis, and what we've learned along the way about why these situations form, why they're harder to fix than they look, and what it actually takes to prevent them from coming back.
The strategies here apply across the board: deviation backlogs, complaint backlogs, CAPA backlogs, and investigation backlogs. The specific procedures differ, but the underlying methodology is the same.
📄 Read our deviation backlog reduction case study to see how we help with these issues through staff augmentation.
Why backlogs are more dangerous than they look
The obvious risk of any backlog is regulatory. Complaints stuck in the queue miss the closeout deadlines. Open deviations put your QMS in a vulnerable position heading into an inspection. That’s real, and it’s serious.
But there are three other risks that are just as important and far less discussed.
Patient safety blindness. Unprocessed complaints mean you’re blind to product performance in the field. Maybe an injection pump with a systemic failure is still in use. The signal is sitting in your system; it’s just buried in the queue. A backlog is essentially a gap in your pharmacovigilance.
The compounding loop. Deviation backlogs directly prevent needed CAPAs from being initiated. We see this all the time. Without CAPAs addressing root causes, the same problems keep generating new deviations. We worked with a pharma company where this dynamic was unmistakable: the backlog was growing at up to 20 deviations a day, and many were recurring failures. The investigation backlog wasn’t just a documentation problem. It was preventing the company from fixing the things causing the deviations. Until you break that loop, the treadmill accelerates.
Double and triple work. Rushing through a backlog (or improperly closing investigations to get the numbers down) is borrowing from the future, and doing your future self a huge disservice. In one project involving roughly 2,500 medical device complaints, we were told at the outset that none of the files required an MDR. That turned out to be significantly wrong. Not only were there overdue reports to file, but the team had to reopen closed complaints to supplement the investigations. As one of our regulatory compliance experts who has worked backlog remediations around the world, put it: “Filling out supplemental forms is like conducting a whole other investigation. You’re doing double and triple the work when you do improper investigation up front.”
A cleared backlog full of inadequate investigations isn’t really cleared. It’s a time bomb that will explode at some point.
Pro tip: Check your trend analysis cadence before you assume the backlog is the problem. Teams in a backlog crisis almost universally discover that their trending program stopped functioning before the backlog became visible. Trending is supposed to catch recurring signals early, the same failure mode appearing in three complaints over two months should trigger action long before it appears in thirty complaints over two years.
When we do the assessment on a backlog project, we routinely find that the trending reports exist but nobody was reviewing them with authority to act. The backlog is often downstream of a broken trending process, not the other way around. Fix the trend review cadence and ownership as part of remediation, or the compounding loop reassembles itself quietly.
Why backlogs form (an honest diagnosis)
Most backlog post-mortems focus on the trigger: the product launch that spiked event volume, the period of high production, the staff turnover that left the team short. But triggers are just that. The real causes are almost always deeper and structural, and they’re consistent across organizations.
Here are the root causes we find most often:
Bandwidth mismatch is the most common culprit by far. Quality teams are staffed for steady-state operations. When workload spikes, from expansion, acquisition, new products, or simply higher production volume, the gap between incoming events and processing capacity opens up. The dangerous thing about this gap is that it’s invisible at first. Files slip by a few days, then a week, then a month. By the time the trend is undeniable, you’re already deep in the hole.
Process inefficiency is another root cause that’s particualrly insidious and amplifies everything. Overly complex procedures, excessive approval cycles, and unclear decision trees slow individual files to a crawl, but often don’t call attention to themselves. We’ve seen complaint handling procedures that require so many layers of review that even a simple, clear complaint takes weeks to close. Ask one diagnostic question to see if you have a problem here: can someone pick up your procedure, read it, and actually execute the process without relying on institutional memory? If the answer is anything but an unqualified yes, the procedure is almost certainly acting an anchor rather than an enabler.
Training gaps show up at every stage, too. In complaint handling, they typically surface at intake. Field techs who can’t distinguish a genuine complaint from a field incident flood the system with non-complaints, stealing time from real investigations. They show up in risk assignment, MDR determinations, and classification decisions, too. When those judgments are made inconsistently, you end up reopening files you thought were closed.
Cross-functional bottlenecks. Quality events roften require input from engineering, manufacturing, or regulatory. When those functions don’t treat event support as a priority, partially completed investigations can sit for weeks waiting for one person’s sign-off. A few stalled files can bottleneck an entire pipeline.
Again, the important distinction here is between the trigger and the root cause. Clearing the backlog without addressing the structural root cause means you’ll be back in the same position in six to twelve months. Pay attention to the triggers, but treat the root causes.
The backlog attack model
Now let’s move to our actual playbook for attacking these backlogs. When we deploy a team for backlog remediation, the approach is consistent whether we're working on deviations, complaints, CAPAs, or investigations. Here's the playbook.
Here’s a look at it.
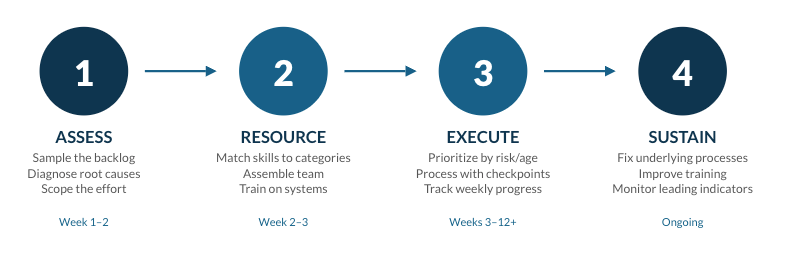
Step 1: Assessment and scoping
The most common mistake in backlog remediation is starting to process files before you understand what you’re dealing with. The assessment phase is not optional overhead — it determines everything that comes after.
Pull a statistically valid sample if possible. Don’t attempt to review everything. That defeats the purpose of moving quickly. The sample analysis tells you what you actually need to know:
What percentage of files are fundamentally sound and just need to be processed through final stages? (This is a very different project from one where investigations are lacking or entirely absent.)
What percentage have inadequate investigations that need to be redone?
Are there classification errors or missed reportability determinations requiring you to reopen supposedly closed files?
What categories of events dominate the backlog, and what expertise does each require?
That last question drives your resource planning (who and how many people you’re going to put on this project). In a large pharma deviation project we were brought in for, we categorized approximately 150 investigations into six areas: automation and engineering, upstream manufacturing, downstream manufacturing, validation/C&Q, utilities engineering, and microbial control. That categorization determined which specialists we needed, how the team was organized, and which items were prioritized first.
Simultaneously evaluate the underlying processes. Ask some very specific questions here:
Where do files stall?
Are procedures adequate and followable?
Is field documentation complete enough to support investigations?
These findings need to be in development as process improvements before the remediation ends, or you’ll rebuild the same backlog.
Build a realistic resource and timeline estimate, and include the CAPAs! This is one of the most common planning errors: organizations calculate resources for the deviation or complaint backlog and forget that clearing it will generate CAPA work. In that same pharma project above, 10 resources handled deviation investigations and 7 additional resources were dedicated specifically to CAPAs and prevention initiatives. If you don’t resource for CAPAs explicitly, you clear one backlog and build another.
Step 2: Team assembly and organization
The people on a backlog project matter enormously. This is not work for whoever happens to have capacity. This is one of the majors reasons firms call on us instead of trying to tackle this themselves: they can bring in one or a few specialists perfectly fitted for each need on contract to work on this without pulling people off of projects.
A few work projects here:
First, match skills to the actual event categories. Technical investigations require technical expertise. In that pharma project, the 7 CAPA resources we brought in were each assigned to a distinct role specifically because of what the deviation analysis revealed about the underlying problems:
an MES editor
an electronic batch record testing and approval lead
a systems lead
an automation engineer
a commissioning/qualification/validation lead
a manufacturing process and development lead
an equipment maintenance and reliability engineer
Every role was driven by the specific nature of what was causing the deviations, not by what people happened to be available.
Pro tip: Put your best investigator on sampling, not processing. The instinct when standing up a remediation team is to put your strongest people directly on closing files since they’re efficient, they produce, and you need throughput. Resist this! Your best investigator is most valuable during the assessment phase, pulling and analyzing the sample.
The quality of the sample analysis determines everything: resource sizing, skill matching, prioritization logic, and whether you catch systematic issues before they propagate. A weak sample analysis that misses a classification problem or underestimates the proportion of files needing rework will cost you far more than the throughput you sacrificed by keeping that person out of the processing queue for two weeks. Use your best judgment up front, then deploy efficiency in execution.
Plan the training investment. If you’re bringing in external resources to augment your team, they need to learn your systems, procedures, and products. A well-designed, intensive one-week training program is typically enough to have qualified people delivering real results by week two. In the pharma project, all 17 resources began on the same day, completed training together, and were delivering on deviation closure by the end of week two. Zero turnover occurred throughout the project.
Structure the team before work begins. Define reporting relationships, quality checkpoints, and escalation paths in advance. Who reviews completed work? Who decides when an item needs escalation? These decisions made upfront prevent the confusion and lost time that comes from resolving them in the middle of execution.
Step 3: Execution
This is the part where you roll up your sleeves and actually make contact with the backlog. Before jumping right in, prioritize before you process. Not all backlog items are equal. Establish clear criteria before the team touches a single file:
Age first. Address the oldest items first. Statute of limitations on reportability is not theoretical.
Risk second. Highest-risk events (complaints suggesting serious patient harm, deviations affecting product quality) move to the front.
